This is an authorized repost of https://chrispisano.wordpress.com/2016/01/18/journey-to-high-availability-2/
Overview
We started with Foreman almost two years ago now because we simply needed a front end to Puppet and the Open Source Puppet Dashboard just didn’t fit the bill at the time. We deployed an all in one implementation as a POC using MySQL and eventually moved into production with a PostgreSQL database and two clustered external Puppet Masters. The Puppet CA lived on Foreman as well as the Smart-Proxy and we set up an unnecessary host group structure with an obscene amount of Smart-Class Parameters; we did not use Hiera at the time. As our environment grew our implementation became slower and slower. We added resources but at the end of the day it was still a single instance running the Puppet CA, Foreman webUI and the ENC/Reports functions. As we grew to over 1,000 hosts (today ~1,800) things got worse; our host groups increased, our Smart-Class Parameters increased and our performance decreased. We lived with this for some time being satisfied with the status quo until we set an initiative to deploy an implementation suitable for an enterprise. It is here where all the fun begins.
If you are interested in watching the live discussion on this topic here is an interview as part of the Foreman Case Study series. Foreman HA Case Study
Requirements
Before the project began we needed to come up with a list of requirements the implementation needed to meet and prioritize what is necessary now and what we can implement in the future. Below is what we came up with.
- High availability at all tiers
- Foreman
- Memcache
- Puppet
- PuppetDB
- CA
- Database
This was the highest priority. We needed our implementation to be up at virtually all times. We also wanted a deployment that allowed us to test updates safely and not have to plan all maintenance for after business hours.
- Built with the latest available versions that we could support
- Foreman 1.9.x
- Puppet 3.8.x
- PostgreSQL 9.x
- CentOS 6.x
We decided that our existing deployment was to be considered legacy and we were going to build everything new. Since we were starting from scratch we decided it would be best to build with the latest and greatest (within reason). Puppet 4 and CentOS 7 were just not doable at this point in time which is why we went with 3.8.x and 6.x respectively.
- Provision new hosts
- VMware
- CentOS/RHEL
- Windows
- AWS
- CentOS
- VMware
We are close to a 100% virtual environment using mostly VMware and some AWS. Deploying hosts from two different tools just wasn’t an option moving forward. We also needed to increase the consistency of our server builds and where the new hosts lived in Foreman.
- Support multiple locations
- Two physical data centers
- AWS
Because we have more than one data center and a private cloud we needed Foreman to support hosts that live in all places. Different product teams servers live in a different combination of locations and we need to be able to distinguish that for access permissions as well as reporting.
- Allow product teams to manage their hosts
- Equivalent of admin rights
- Only to the hosts they own
One of our main goals is to empower our product teams to manage their servers without having our Infrastructure Operations team be a bottleneck. In order to achieve this we need to have an organized structure of locations/organizations/host groups as well as role based access controls for users.
- Integrate with DHCP and DNS
- Clustered MS DHCP
- One cluster in our main data center
- MS DNS
- DNS servers per location
- Clustered MS DHCP
Part of the goal is to have Foreman manage our servers lifecycle and increase our efficiency and consistency in provisioning. We can provision without IP addresses and nobody is going to remember the IP addresses of all of their servers. An added benefit is that Foreman cleans these up when hosts are destroyed; something humans rarely do. . . or at least remember to do.
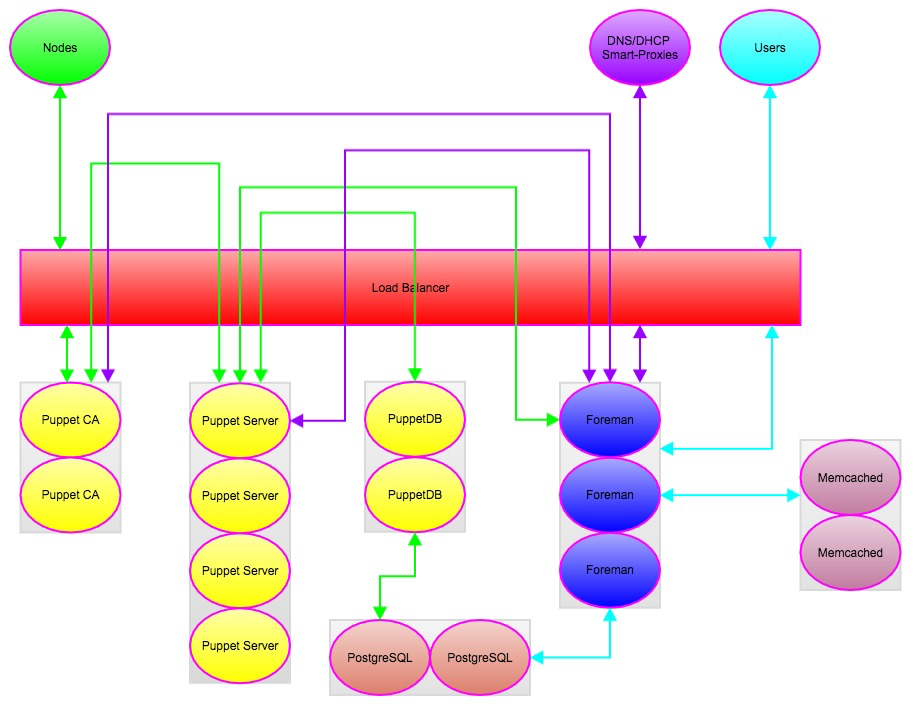
The Implementation
Building the Infrastructure
I will discuss building the entire deployment with the exception of the database. Our Enterprise Data Management team built and maintains our PostgreSQL backend; we just have a username, database name and password to connect with. They are using PostgreSQL 9.x and utilizing PG_Pool for high availability.
Foreman and Memcache (The fun stuff)
The first thing we needed to do before building out our Foreman cluster was to actually figure out what was needed and how Foreman works on a deeper level. Naturally the first move was to go directly to the community in IRC and the Google groups to consult with others that know more than I do. There are two ways you can build your Foreman cluster; a single cluster for all functions or two separate clusters broken out for ENC/Reporting and a webUI. After doing some research into each we decided to go with the simpler single cluster knowing that in the future (sooner than we are expecting) we will need to build a second cluster dedicated to ENC/Reporting functions. Luckily this is an easy change in architecture to implement and can be done with little impact. That is for another post though, so I will focus on what we ended up doing. After some consideration we decided to go with a three node cluster (by the time this gets published it might very well be a four node cluster). We were going to originally go with a two node cluster but since our legacy stuff makes heavy use of smart-class parameters we wanted the extra node to help spread the load rendering all of the ENC data for hosts we aren’t going to migrate to our new code base. We also learned that Foreman stores it’s sessions in the database so loadbalancing wasn’t going to be as complex as we originally thought and we could actually look at implementing some cool things in the future since we don’t need to implement any type of persistence. Another important thing to know is that each Foreman server will have their hostname based Puppet certificate, but for clustering you will need to generate a generically named certificate to be distributed across your Foreman servers and used for the webUI and ENC/Reporting functions. We generated the certificate based on the URL name we were going to use.
It was realized pretty late in the implementation that memcache was going to be necessary to function properly. We found out that Foreman keeps a local cache of certain information that it will default to rather than continually making calls to the database. Having a multi-node cluster would mean that any of this information could be or could not be in sync at any given point in time. So to work around that we implemented two memcache servers and the foreman_memcache plugin. Between the plugin and the memcache Puppet module the setup couldn’t have been simpler and all of our data and information was kept in sync without issue across our nodes. The two memcache servers we built we kept outside the load balancer (Foreman talks directly to them) since it is not necessary given the way memcache works.
When it came time to configuring the loadbalancer for our Foreman cluster it was pretty straight forward. We decided to do SSL passthrough though that will most likely change in the near future. We have the loadbalancer configured to pass traffic on ports 80 and 443 however we initially set up a 443 redirect which caused some provisioning issues. Basically we had it so any http traffic to Foreman that came in on the load balancer we redirected to port 443 which broke some provisioning functionality (user_data for us) since it only works over http. Once we removed the redirect rule from the loadbalancer all provisioning issues resolved. We also temporarily ran into some authentication issues which originally seemed sporadic but we soon figured out that authentication was only working on one of our Foreman hosts. Once again by going to the community in IRC we quickly learned (and should have realized) that we needed to have the same encryption_key.rb file distributed across all Foreman hosts. We distributed the file from the working Foreman host to the others, restarted the service and all authentication issues were resolved.
At this point we successfully had Foreman clustered. We were able to drop nodes from the load balancer, restart services and power cycle hosts without impacting availability or performance. This was just one peice of our implementation though; we still needed our Smart-Proxies and our Puppet infrastructure.
Smart-Proxy
We are currently using three forms of the Foreman Smart-Proxy; Puppet, PuppetCA, DHCP. We are looking to implement DNS soon but were unable to complete it during this timeframe. All of our Smart-Proxies are configured to talk to the URL of our Foreman cluster that passes traffic through the load balancer.
We were fairly new to using the DHCP Smart-Proxy and were a little unsure of how the setup and configuration was going to go. To our somewhat surprise it went rather smooth only running into two minor issues. We run MS DHCP so I quickly learned a good amount about Windows and what was needed to install and run the Smart-Proxy on a Windows host. The documentation in the manual is very good and made the install and configuration very simple. We hit two bugs which are known and hopefully we can help contribute patches to resolve them. The first was with the Smart-Proxy showing the DHCP reservations as leases and not having showing the hostnames which is tracked as bug #10556. The other bug we hit was that the Smart-Proxy does not honor DHCP exclusions which is tracked as bug #4171. Besides those two issues everything went as expected; we were able to implement a work around for each. The first issue has a work around in the ticket and we worked around the second by being able to utilize previously unused ip space in our /23 subnets. Since we installed the Smart-Proxy on MS Server 2012R2 we did get some deprecation warning from Microsoft about netsh which we filed an issue for that is tracked as refactor #12394.
Setting up the Smart-Proxy on the Puppet CA servers was pretty straight forward and we were very familiar with it from our previous implementation. The main difference this time around was that we were going to have clustered Puppet CA servers so we needed to run a Smart-Proxy on each. We installed the Smart-Proxy via the foreman-installer and used a genericly named certificate that we can put on each host. Since the Puppet CA servers are behind a load balancer we needed to configure the load balancer to also pass traffic on 8443 for the Smart-Proxy. The Puppet CA cluster is configured to be active/passive with shared storage for the certificates so all requests will hit one host unless it becomes unavailable.
We are also very familiar setting up the Smart-Proxy on our Puppet servers so this was fairly trivial as well. We had previous experience setting up the Smart-Proxy on clustered Puppet masters so we followed the same process as before; genericly named certificate distributed across our Puppet servers and the Smart-Proxy installed and configured via the foreman-installer. We did implement the puppetrun feature of the Smart-Proxy utilizing puppet_ssh so we had to orchestrate the distribution of the ssh keys for the service account we planned on using. Again since our Puppet servers were to be load balanced we had to allow the load balancer to pass traffic on 8443 as well. The Puppet server cluster has all nodes active at all times so requests well be spread across any available node.
As I stated earlier future plans are to implement the DNS Smart-Proxy as well as implement the MS DHCP cluster ability in Server 2012R2 and then clustering the DHCP Smart-Proxy.
Puppet
I will not go into great detail about our Puppet implementation since this is a blog posting for Foreman but I will give enough of an overview to gain a decent understanding of how to build highly available Puppet. If you have any questions or just want to chat about this type of implementation and what we ran into/did in more detail feel free to ping me on IRC. Username: discr33t.
The foreman-installer makes this very easy since it can be used to configure your Puppet masters and Puppet CA. We started by building four Puppet masters using Puppet Server v1. This will ease our upgrade to Puppet 4 when the time comes and for the time being give us better performance and tuning capabilities of our masters. Since we wanted to have the CA separate from the masters we set CA => false and specified the DNS name of what we wanted our CA server to be.
When going through the installer be sure to not use the hostname for any certificates for the Puppet masters, CA servers or PuppetDB servers. Since we are clustering everything we will be use generically named certificates that we will be generating on our CA. This will allow the certificate to be verified when requests hit any of the hosts in the cluster. Each of the Puppet masters, CA servers and PuppetDB servers will use their hostname based certificates when running the Puppet agent. The server setting should be set to the name of your generic certificate for your Puppet masters; similar to what you did for the CA.
On your load balancer of choice you will want to add all of your Puppet masters and allow the load balancer to pass traffic on ports 8443 (Smart-Proxy) and 8140 (Puppet). You should configure your load balancer so all nodes are active. If you are using version control for your code and a continuous integration server for deployments you might want to look into setting up shared storage for your Puppet environments (we did with NFS on our NetApp) and allow the load balancers to pass traffic on port 22 so your continuous integration server can log in and run your scripts to pull code. Another option would be to use a tool such as r10k.
While on the topic of shared storage for your Puppet masters it is not necessary but you should use shared storage for /var/lib/puppet/yaml. If you don’t you will receive a warning message until the Puppet agent for every host checks into each Puppet master at least once.
Again we used the foreman-installer for our CA servers and mostly followed the same process. We wanted to use Puppet Server V1, a generic name for the certificate to be used and the Foreman Smart-Proxy installed. The differences are that now we want CA => true and for the Smart-Proxy you want to only enable the puppetca module. The load balancer configuration is almost identical with the exception of port 22 and you want an active/passive configuration rather than an active/active. This is because the inventory.txt file is not locked when the process runs and active/active risks corruption. You will still need to keep /var/lib/puppet/ssl in sync between the two CA servers. There are many ways to do this but we chose shared storage.
We wanted to institute PuppetDB for the insight it will give us into our environment and for some of the advanced features it offers. We used the PuppetDB module to install and configure both PuppetDB servers, and the configuration for PuppetDB on our Puppet masters. Just like the CA servers and the Puppet masters we want to use a generically named certificates for the PuppetDB servers. There is no Smart-Proxy configuration necessary here, but PuppetDB does need to have a database backend. We chose to have our Enterprise Data Management team give us another database on the same cluster Foreman will use. The load balancer configuration is pretty straight forward; we did active/active passing traffic for ports 8080 (http for the dashboard) and 8081 (https for Puppet).
Once you have these three peices functional a big congratulations is in order because you have just built a highly available implementation of Puppet! Though PuppetDB is not necessary it is the icing on the cake for this part.
Conclusion
Through all of this we have managed to build a highly available implementation of Foreman and Puppet to help us provision and manage our infrastructure. So far things are going well but there is more we want to do and will need to do as our environment grows. We are no longer using Smart-Class parameters and are fully utilizing Hiera, though we make use of some custom made parameters in Foreman to build a better Hiera hierarchy for our environment. I hope this is helpful reading to others looking to achieve the same or similar implementations. I can’t thank the Foreman community enough for their continued help. Keep an eye out for future blog posts for how we are using Foreman to help us implement an infrastructure as a service model within our firm. An architecture diagram of our final product is linked below for those interested.